AI voice impersonation: voice-based authentication just got owned
Does the voice you recognize at the end of the phone really belong to the person you think it is? Find out what AI voice impersonation is.
Does the voice you recognize at the end of the phone really belong to the person you think it is? Find out what AI voice impersonation is.

Does the voice you recognize at the end of the phone really belong to the person you think it is?
I’m Ian, one of the Red Team Swarm members at CovertSwarm. My role is simple. My goal every single day is to compromise the security of our clients.
All the current hype around artificial intelligence (AI) got me thinking: could I impersonate someone else’s voice using AI and the latest machine learning models? Well, turns out I can.
This blog is very much a ‘proof of concept’ to demonstrate the process, but here at CovertSwarm we are already using these techniques against our customers.
We’re calling helpdesks, pretending to be people they know in order to get passwords reset and accounts breached. This often defeats additional verification checks because they recognize the person calling!
AI voice impersonation refers to the use of artificial intelligence (AI) technology to mimic or imitate the voice of a specific person or to generate synthetic voices that sound like real individuals. It involves training AI models using large amounts of audio data from the target person to capture their unique vocal characteristics, such as pitch, intonation, and speaking style.
AI voice impersonation can be considered a social engineering technique, because it involves manipulating and deceiving individuals to gain access to confidential information, systems, or resources. By impersonating someone’s voice using AI technology, hackers can exploit the trust and familiarity individuals have with the targeted person to trick them into revealing sensitive information or performing certain actions.
With advancements in deep learning and neural network-based techniques, AI voice impersonation has become more sophisticated and capable of producing highly convincing results. These systems can analyze the acoustic features and patterns in a person’s voice and generate synthetic audio that closely resembles their speaking style and tone.
AI voice impersonation has various applications, including in the entertainment industry for creating voice overs, dubbing, and character voices. It can also be used for text-to-speech (TTS) systems to generate more natural and personalized synthetic voices.
However, it’s important to note that AI voice impersonation also raises ethical concerns, as it can potentially be used for malicious purposes such as deepfake audio or voice fraud.
My initial proof of concept was to use Anders Reeves, CovertSwarm’s Founder and CEO as a target. This was primarily because I have familiarity with his voice and combined with the Swarm, we’d soon work out if this attack was viable or not.
Also, there is a fair bit of source material on the internet from Anders, not least from our promotional videos on YouTube and podcasts. If you haven’t checked out our podcasts yet, then you are really missing out!
After some research into AI voice conversion software, looking at locally hosted open source options and online resources, I decided to use ElevenLabs’ Speech Synthesis system, which turned out to be pretty freaking amazing! This was primarily for the quality, speed, and ease of use for this research.
This post is not aimed at a highly technical level so I will lightly cover the technical aspects of how this was achieved and culminating in the results.
The main starting point was gaining source material to use for the synthetic voice. I used a combination of video references available on the internet and podcast material.

These online files were then downloaded and converted into usable audio and video files. The video files were split into audio and video files with the video ones then discarded.
Short sections of differing audio where possible were identified. For example, more formal speech, more light-hearted, and various snippets with as much differing inflection as I could find. As this was a proof of concept only a small number of files were used for this initial phase.
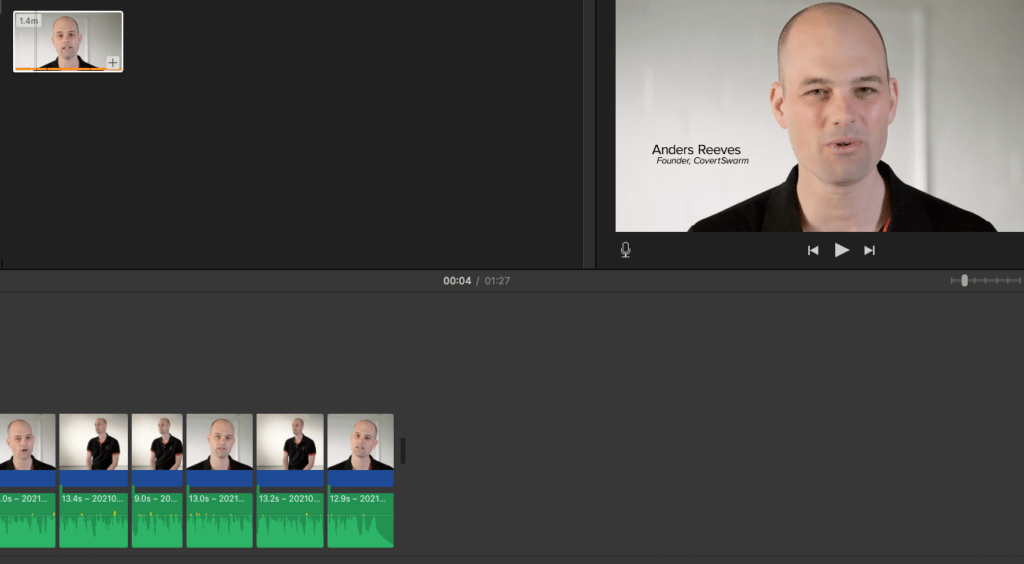
Once I had some source files, I loaded these into the voice synthesis software. Then after the “model” was generated using the software’s AI and deep learning algorithms, I had a starting point to work from to adjust the voice to a more lifelike sounding sample.
One of the limitations of the “base” level of ElevenLabs’ subscription is limited controls over the voice adjustment. Also, the voice must be “generated” for each adjustment which means you have to view adjustments differently to a more usual control set.
For example, to make the voice more expressive, you need to have a more varied voice generation each time the voice is generated to say different content. This part can take quite a bit of adjustment.
Also, the “script” you would like the generated voice to say can have an impact in the way you generate the voice. Longer pieces of text can sound more monotone where they sounded more realistic to a shorter sentence.
Changes to the way the text is formatted can help to make the voice sound more authentic such as pauses and emphasis on certain words. This element of adjustment is still being improved upon as is the entire process which is very new and changing rapidly.
Even at this early stage in the AI voice generation process, creating a lifelike voice representation, the results are very impressive, if somewhat unnerving. The generated voice is not an exact match but is very similar.
The results of this part of the proof of concept are illustrated in the sound files below:
Original audio from a source podcast
AI generated copy of the original audio
The following is an illustration of using the voice to say whatever you want.
Attempting to simulate a British accented voice like Anders is quite a hard test for AI voice generation but demonstrates what is currently possible. Generating an American accent is currently a lot easier.
Recent developments are being implemented to improve different accents and languages in the AI voice generation. If someone just wanted to create a voice that sounds like a real person this proves it is currently possible and quite easy and cheap to do.
This brings me on to ways how this technology could be abused and used by malicious actors (and CovertSwarm’s ethical hackers) to compromise organizations.
There are methods such as the pre-recorded automated phone calls I’m sure you all get pretending to be from a bank or a support company and attempting to extort money from people. If a real sounding human voice was used this would make the phone call sound more convincing.
A more sinister attack approach could be a targeted vishing attack, where an attacker uses a phone call pretending to be a family member in distress and giving a story where they needed money quickly.
Across a phone line with its degradation in voice quality, this technology could easily be used to lure a person into sending money quickly to aid them. An approach to counter this type of attack could be to use safe words or passcodes known only to family members.
Again, businesses could be targeted in a similar manner and attempts to exfiltrate sensitive information or system access through vishing attacks by impersonating a high-level employee could be used or one of our current favorites… calling helpdesks and getting passwords reset!
Having now achieved a quite lifelike copy of a voice, I wanted to examine the current real-world possibilities of using a fake voice to perform a simulated vishing attack.
Using open source Voice Over IP (VoIP) SIP phone software, we were able to configure this to spoof a mobile number easily. Nothing new here – in fact, we use it all the time to call people from numbers they will recognize, such as calling the helpdesk from the CISOs mobile to get their password reset.
I investigated two potential methods of delivering this type of attack:
For the purposes of this part I investigated the second option. The soundboard option will be a great option for a known method of attack, but I wanted to investigate if real time voice changing was possible.
Configuring my laptop to have an additional virtual sound device I was able to channel computer generated audio into the software VoIP phone.
After some investigation I found an open-source script that utilized the API for ElevenLabs, this enabled me to run a local web application and capture my speech. This in turn created the text to send to the API and converted in real time the spoken text to whatever voice I had created and selected in my ElevenLabs account.
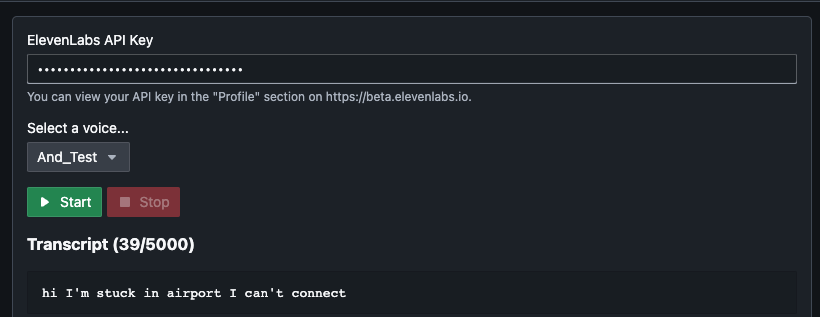
I configured the VoIP to accept my virtual audio adapter as input and it channeled through audio to the phone number I had called. This effectively enabled me to talk as Anders.
It’s early days, but these attacks are very real! So, what can you do as an organization to help mitigate vishing attacks?
By implementing these measures, organizations can significantly reduce the risk of falling victim to vishing attacks and enhance their overall security posture.
If you have any further questions about AI voice impersonation or need advice on how to prevent vishing attacks, please don’t hesitate to contact us!

Vishing: everything you need to know
Read our guide to find out what vishing is, how it works, why it exists & how to identify, respond to, recover from & prevent it.

Multi-Factor Authentication (MFA): what you need to know
Read our blog to find out what Multi-Factor Authentication (MFA) is, why it’s vital to have it and how AI makes it more secure & efficient.

What is ethical hacking?
Read our guide about ethical hacking to find out what it is, why it’s important, its benefits and challenges and much more.